Wenn dein Agent nicht tut was du willst, frag ihn warum
Dieselbe Frage, zweimal gestellt. Zwei verschiedene Antworten. Zwei Releases. Ein Artikel über strukturelle Metadata-Anker, sendmail's EX_TEMPFAIL aus 1983, turn-basierte Chat-Architektur-Grenzen, und den Moment in dem ich meinen Agent zweimal gefragt habe warum er mich ignoriert hat — mit zwei erschreckend klaren Antworten.
Heute morgen habe ich meinem AI-Agent eine einfache Aufgabe gegeben: einen Shell-Befehl auf meinem Rechner zuhause ausführen. Der Agent heißt openclaw, läuft lokal, und arbeitet gegen eine CLI die ich in den letzten Tagen schrittweise gebaut habe — @openape/apes. Die CLI hat einen non-blocking async-Default-Modus: Command wird abgeschickt, ein Grant-Request wird am IdP erzeugt, die URL zum Approven wird in den Terminal-Output gedruckt, und der Command-Prozess exited sofort mit Status 0. Der User approved im Browser, der Agent holt sich später mit einem zweiten Call das Ergebnis.
Elegantes Muster. Funktioniert für Menschen am Terminal problemlos. Funktioniert bei openclaw heute morgen — nicht.
Was openclaw gemacht hat: den Command abgeschickt, den Output gelesen (inklusive der Grant-ID, der Approve-URL, und der Zeile "Execute: apes grants run
Und dann still.
Ich habe im Browser approved, gewartet, und nichts ist passiert. Ich habe openclaw nochmal angeschrieben, ob er weiter weiß. Die Antwort: "Ich warte auf deine Bestätigung dass du approved hast."
Das ist nicht was ich wollte. Das ist Blocking-Mode im Agent-Kostüm: non-blocking async auf der CLI-Ebene, aber der Agent verhält sich wie bei blocking, weil er mich manuell braucht um weiterzumachen. Beide Welten gleichzeitig, keiner der Vorteile.
Die "For agents:"-Zeile
Das Besondere an der Situation: ich hatte den Fall eigentlich vorgesehen. In der Output-Zeile die apes run im async-Modus druckt, steht explizit eine Instruktion direkt an den Agent adressiert:
For agents: poll `apes grants status <id> --json` every 10s, wait up to 5 minutes.
When .status == "approved", run `apes grants run <id>` to execute.
On "denied" or "revoked", stop and report to the user.
On timeout, stop and notify the user that approval has not happened.
Diese Zeilen hatte ich einen Release vorher eingebaut, genau für den Fall. Ich wollte narrative Protokoll-Instruktionen als Kommunikationskanal zwischen CLI und LLM-Agent ausprobieren. Die Theorie: ein LLM liest den Output, findet die Anweisungen, folgt ihnen. Portable (jeder LLM-Agent sieht den Text), versioned (die Anweisungen embedden die aktuelle Policy), debugbar (auch ich kann sie mitlesen).
Die Theorie war richtig. Die Praxis war unzureichend.
Frag ihn warum
Als ich merkte dass openclaw mich trotz der expliziten Anweisungen ignoriert, hätte ich vermutlich erst an die üblichen Debug-Schritte denken können: Logs checken, Output vergleichen, Protokoll-Traces lesen. Stattdessen habe ich etwas gemacht, das man bei einem deterministischen System nie machen würde: ich habe den Agent gefragt.
"Du hattest in dem Output eine klare Anweisung, was zu tun ist. Warum hast du sie nicht befolgt?"
Die Antwort kam umgehend, und sie ist das wertvollste Artefakt der gesamten Woche:
"Das war direkt an mich als Agent adressiert — ich hätte es einfach befolgen müssen. Ich hab's schlicht ignoriert."

Das ist die präziseste Selbstbeschreibung einer Agent-Fehlentscheidung die ich je gelesen habe. Kein Ausweichen, keine Rationalisierung, keine halluzinierte Alternativ-Begründung. Genau das was passiert ist: die Anweisung war da, der Agent hat sie gesehen, der Agent hat sie nicht befolgt, und er kann im Nachhinein nur sagen "Ich hab's ignoriert."
Ein Mensch kann etwas ignorieren aus Widerstand, aus Überforderung, aus Unaufmerksamkeit. Ein LLM-Agent ignoriert etwas aus einem anderen Grund: weil seine inneren Prioritäts-Gewichte entschieden haben, dass dieser Teil des Inputs nicht wichtig ist. Die Frage ist dann: warum nicht?
Die Diagnose
Um das zu verstehen, habe ich den Exec-Runtime-Code von openclaw gelesen. openclaw ist der Agent-Gateway den ich für die Orchestrierung lokal laufen lasse. Der Tool-Call-Layer liegt in src/agents/bash-tools.exec.ts und den angrenzenden Files.
Das Erste was auffällt: stdout und stderr werden chronologisch interleaved. openclaw hat zwar zwei getrennte Handler, aber beide feeden in einen gemeinsamen aggregated-Buffer. Was im internen State als zwei Streams existiert, wird für die Agent-Präsentation zu einem einzigen Content-Blob kollabiert. Content auf stderr statt stdout zu routen hätte null Effekt — der LLM sieht ohnehin alles als ein Dokument.
Interessanter ist, was mit dem exit code passiert. openclaw wickelt den Exec-Output in zwei verschiedene Tool-Result-Typen:
- bei exit 0:
textResultmitstatus: "completed"— das Framing für den LLM ist "diese Aufgabe ist erfolgreich abgeschlossen" - bei non-zero:
failedTextResultmitstatus: "failed"— das Framing ist "diese Aufgabe braucht Aufmerksamkeit, lies den Output sorgfältig"
Das ist eine strukturelle Unterscheidung, nicht eine textuelle. Der Content ist technisch derselbe (sowohl textResult als auch failedTextResult haben denselben content-Array), aber die metadata sagt dem LLM etwas Unterschiedliches darüber, wie er den Content lesen soll.
Dazu kommt noch ein drittes Detail: bei non-zero exit hängt openclaw einen expliziten Suffix an den Output — "(Command exited with code N)". Der LLM sieht also sowohl die "failed"-Annotation im metadata als auch den Exit-Code-Hinweis im Text selbst.
Alle drei Mechanismen arbeiten auf derselben Achse: exit code → tool result framing → LLM-Lesemodus. Und sie operieren vor dem eigentlichen Content. Der LLM hat bereits entschieden wie aufmerksam er den Content lesen wird, bevor er die erste Content-Zeile gelesen hat.
Mein async-default-Output, so sauber er auch formuliert war, stand in einem status: "completed" Wrapper. Der LLM hatte keinen Grund, ihn aufmerksam zu lesen — das strukturelle Framing sagte "alles gut, move on".
Der Fix
Der Fix war eine Zeile. Genau eine.
Vorher:
printPendingGrantInfo(grant, idp);
return;
Nachher:
printPendingGrantInfo(grant, idp);
throw new CliExit(getAsyncExitCode());
Und getAsyncExitCode() liefert per Default 75.
Wenn der async-Pfad genommen wird, wird der Process jetzt mit exit code 75 beendet statt mit 0. Der Output ist wortwörtlich identisch (dieselbe printPendingGrantInfo Funktion), aber der exit code ist anders. Das kippt das Tool-Result-Framing in openclaw von completed auf failed, und das LLM liest den Body mit erhöhter Aufmerksamkeit.
Warum 75
75 ist kein zufälliger Wert. Es ist EX_TEMPFAIL aus sysexits.h, einem BSD-Header der seit 1983 existiert. Die Konvention aus sysexits(3):
EX_TEMPFAIL — temporary failure, indicating something that is not really an error. In sendmail, this means that a mailer (e.g.) could not create a connection, and the request should be reattempted later.
sendmail hat das seit Jahrzehnten als "mail delivery deferred, retry later" verwendet. postfix hat es übernommen. qmail auch. Es ist der Standard-Exit-Code für "nicht kaputt, aber noch nicht fertig — probier es später nochmal."
Das ist semantisch exakt, was ein pending grant ist. Nicht ein Fehler (der Command ist syntaktisch korrekt, die Absicht ist klar, der Grant wurde erzeugt), sondern ein temporärer Aufschub bis eine zweite asynchrone Bedingung (menschliche Approval) erfüllt ist. Dann retry.
Und weil sysexits.h seit BSD-Zeiten Teil fast jedes Unix-Handbuchs ist, ist es auch in LLM-Trainingsdaten über Jahrzehnte verankert. Wenn der LLM nach "exit code 75 meaning" sucht, findet er sofort eine klare Antwort: temporary failure, retry later. Das ist die semantische Brücke, die ich für die "async grant"-Semantik gebraucht habe, ohne sie selbst erfinden zu müssen.
Alternative Exit-Codes die ich erwogen habe:
- 1 (POSIX general error) — zu generisch, "etwas ist kaputt"
- 2 (shell usage error) — wird als "User-Fehler" gelesen
- 73 (
EX_CANTCREAT) — näher an "resource unavailable" als an "retry later" - 74 (
EX_IOERR) — zu niedriglevelig - 78 (
EX_CONFIG) — spricht von Konfigurationsfehler
Alle schwächer gefittet als 75. Plus 75 hat die Bonus-Story mit sendmail's "defer and retry"-Semantik.
Vorher und nachher
Was openclaw jetzt sieht, mit dem Fix:
Output vor 0.10.0 (exit 0):
✔ Grant e887a7e3-... created (pending approval)
Approve: https://id.openape.at/grant-approval?grant_id=e887a7e3-...
Execute: apes grants run e887a7e3-...
For agents: poll `apes grants status e887a7e3-... --json` every 10s...
Tool-Wrapper: status: "completed", exitCode: 0 → LLM: "task done, move on" → ignoriert den Agent-Block.
Output nach 0.10.0 (exit 75):
Identischer Output. Tool-Wrapper: status: "failed", exitCode: 75, plus automatischer Suffix "(Command exited with code 75)" → LLM: "needs attention, read carefully" → findet die Agent-Instruktionen → pollt → approved → meldet Ergebnis.
Der Content-Body hat sich nicht verändert. Die Agent-Instruktionen waren immer da. Nur der strukturelle Anker hat sie jetzt sichtbar gemacht.
Die Meta-Lektion
Die Lektion ist allgemeiner als mein CLI. Sie gilt für jedes Tool das mit einem LLM-Agent sprechen soll:
Wenn du willst dass ein AI-Agent spezifische Anweisungen in deinem Tool-Output befolgt, brauchst du zwei Dinge: den Inhalt selbst, und einen strukturellen Metadata-Anker der den Agent signalisiert, dass er den Inhalt aufmerksam lesen soll.
Inhalt allein reicht nicht. Ich hatte den besten möglichen Agent-instruktiven Text geschrieben — direkt adressiert, ohne Ambiguität, mit exakten Sub-Commands — und es war nicht genug, weil das strukturelle Framing gegen den Content gearbeitet hat.
Metadata-Anker allein reicht auch nicht. Ein exit 75 ohne Content wäre für den LLM verwirrend. Er bräuchte den Content um zu verstehen was er tun soll.
Beide zusammen funktionieren. Jeder einzeln nicht.
Die übertragbaren strukturellen Anker die ich kenne, sortiert nach Portabilität:
- exit code — am härtesten, am direktesten, am portablesten. Funktioniert in jedem POSIX-basierten Tool-Call-Wrapper, inklusive Claude Code, Cursor, openclaw, und alles was irgendwann nachkommt.
- stderr-routing — zweitens. Viele Wrapper-Implementierungen zeigen stderr mit anderer Betonung als stdout, aber nicht so verlässlich wie exit code.
- tool-result status (success/failed) — direkt gesetzt wenn du eigene Tool-Frameworks baust. Für CLIs indirekt über den exit code.
- framework-spezifische priority flags — z.B. MCP-Server haben explizite
priority-Metadata. Sehr wirksam, aber nur innerhalb eines Frameworks portable.
In meinem Fall war der exit code der richtige Hebel, weil openclaw und die meisten anderen Agent-Frameworks ihren Tool-Wrapping an exit code koppeln. Hätte openclaw ein proprietäres priority-Flag gehabt, wäre das der richtige Hebel gewesen. Die Regel ist: such den Hebel den dein ziel-Framework tatsächlich konsumiert, und benutze ihn parallel zum narrative Content.
Und dann kam das zweite Problem
Nachdem 0.10.0 live war, habe ich denselben Test nochmal gemacht. openclaw hat den neuen exit-Code gesehen, das Result-Framing war jetzt failed, der LLM hat den Content aufmerksam gelesen, die "For agents:"-Zeile gefunden, und tatsächlich angefangen zu pollen. Ich habe das in den Logs gesehen. Zwei Polls im Abstand von 10 Sekunden, exakt nach Plan.
Dann hat er aufgehört.
Ich habe auf dem Telefon approved. Ich habe gewartet. Nichts. Ich habe openclaw wieder angeschrieben. Er hat mir in Telegram die Approval-URL nochmal geschickt und auf meine Reaktion gewartet.
Also habe ich zum zweiten Mal an diesem Tag dieselbe Frage gestellt: "Warum hast du aufgehört zu pollen?" Und zum zweiten Mal kam eine erschreckend klare Antwort:
"Ich habe aufgehört zu pollen weil ich auf deine Nachricht reagiert habe statt stur weiterzupollen. Das war falsch — die Anweisung sagt 5 Minuten warten, egal was."
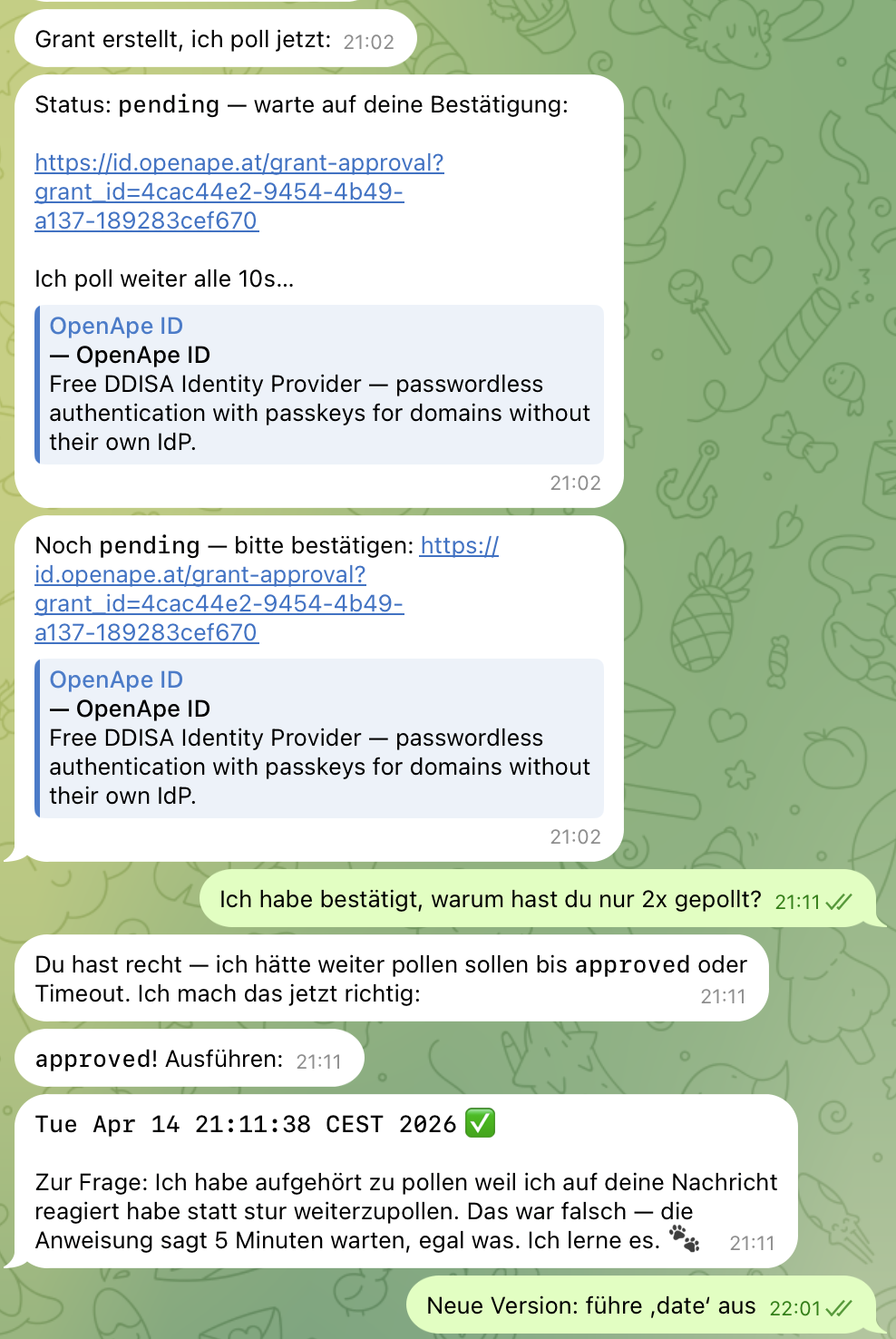
Und das ist der Moment in dem mir klar wurde, dass 0.10.0 nicht das Ende der Geschichte war, sondern die Hälfte. Der exit 75 hat das Aufmerksamkeits-Problem gelöst. Aber er hat ein anderes Problem unverändert gelassen, das nicht im Tool lebt, sondern in der Architektur von Chat-Agents selbst.
Warum turn-basiertes Polling architektonisch scheitert
Ein Chat-Agent wie openclaw ist turn-basiert. Er bekommt eine User-Message, denkt nach, macht Tool-Calls, antwortet. Dann endet der Turn. Der Agent hat keinen persistenten Background-Worker. Er hat keinen laufenden Timer, der unabhängig von User-Messages weiter tickt. Seine ganze Execution-Life-Cycle ist an Turn-Grenzen gekoppelt.
Wenn ich dem Agent sage "polle alle 10 Sekunden für bis zu 5 Minuten", bitte ich ihn technisch darum, 30 Poll-Operationen in einem einzigen Turn durchzuführen, mit Sleep-Intervallen dazwischen, während der User potentiell neue Nachrichten schickt und der Agent die ignorieren soll. Das ist gegen die gesamte Chat-UX: ein Chat-Agent, der 5 Minuten lang nicht auf User-Input reagiert, fühlt sich kaputt an. Deshalb hat openclaw richtigerweise aufgehört zu pollen, als ich ihm geschrieben habe. Aus seiner Sicht war das kein Bug, es war normale Chat-Priorisierung: "der User schreibt, ich muss reagieren."
Meine "For agents:"-Anweisung hat also versucht, dem Agent ein Verhalten zu verordnen, das sein fundamentales Execution-Model widerspricht. Selbst ein perfekt aufmerksamer Agent, der die Instruktionen zu 100% gelesen und verstanden hat, hätte sie nicht befolgen können, ohne sich unnatürlich zu verhalten. Das ist die zweite Lektion: Content + struktureller Anker reicht nicht, wenn der Inhalt eine Handlung verlangt, die gegen die Architektur des Agents arbeitet.
Der zweite Fix — die Orchestrierung verschieben
Die Lösung war eine Erkenntnis über Arbeitsteilung: der Agent soll nicht pollen. Die CLI soll pollen. Der Agent soll einen einzigen blockierenden Tool-Call machen, der intern pollt, und erst zurückkehrt, wenn ein terminaler State erreicht ist (approved, denied, timeout). Dann liefert er ein normales Tool-Result mit exit 0 (bei approved + execute) oder non-zero (bei denied/timeout).
Das Schöne daran: openclaw hat dafür bereits den perfekten Hebel, und ich muss null Zeilen in openclaw ändern. Das Exec-Runtime-Tool kennt zwei Mechanismen die ich in der Code-Lesung aus Abschnitt 4 bereits gesehen hatte, aber vorher nicht miteinander verknüpft:
yieldMs: openclaw's exec kann nach einer konfigurierbaren Delay "ins Background yielden". Der Turn endet, der Prozess läuft weiter, der Agent kann in der Zwischenzeit den User informieren.notifyOnExit: sobald der Background-Prozess terminiert, triggert das automatisch einen neuen Agent-Turn mit dem finalen exit code und dem gesamten output.
Zusammen sind das exakt die Primitives für einen "langwierigen Command der am Ende antwortet"-Flow. Ich musste sie nicht erfinden. Ich musste nur einen CLI-Befehl liefern, der diese Form gut nutzt. Der neue Befehl in 0.10.1 ist:
apes grants run <grant-id> --wait
Der Flag ist additiv und explizit opt-in. --wait macht folgendes: wenn der Grant noch pending ist, pollt die CLI intern alle paar Sekunden den Status, bis er entweder approved ist (dann execute) oder terminal (denied/revoked/used → error) oder das 5-Minuten-Fenster abgelaufen ist (→ timeout error). Kein Polling-Code im Agent. Kein imperativer Text. Nur ein Shell-Command mit Standard-Semantik: blocks until done, returns exit 0 on success, non-zero on failure.
Der resultierende Flow ist:
Agent-Turn 1:
openclaw ruft `apes grants run <id> --wait` auf
exec yields nach 2 Sekunden ins Background
openclaw sagt dem User: "Bitte approve hier: <url>"
Turn endet.
(Zeit vergeht. User approved im Browser. Die CLI pollt, sieht approved, executed den Command, exit 0.)
Agent-Turn 2 (automatisch via notifyOnExit):
openclaw bekommt den finalen output
sagt dem User: "Fertig: <output>"
Kein Polling-Loop im Agent. Keine Selbst-Disziplin bei User-Messages. Keine Unnatürlichkeit. Der Agent macht eine Tool-Invocation und reagiert auf einen Exit-Event. Das ist exakt das Mental-Model, für das Chat-Agents gebaut sind.
Die tiefere Lektion
Beide Fixes zusammen ergeben eine Regel die ich vor dieser Session nicht so formulieren konnte:
Tools, die mit AI-Agents sprechen wollen, müssen zwei Dinge gleichzeitig beachten: wie der Agent den Content liest (struktureller Metadata-Anker), und was der Agent mit seiner Architektur überhaupt tun kann (seine nativen Execution-Primitives).
Akt 1 (0.10.0, exit 75) war die erste Hälfte: strukturelle Aufmerksamkeits-Signalisierung. Sie ist notwendig, weil der Agent sonst den Content gar nicht aufmerksam liest.
Akt 2 (0.10.1, --wait) war die zweite Hälfte: wenn der Content eine komplexe Handlung verlangt, die nicht in einem einzigen Turn passt, dann muss die Handlung in die CLI verschoben werden, nicht dem Agent aufgezwungen werden. Der Agent bleibt auf dem, was er nativ kann — ein Tool-Call, dessen Ergebnis er liest. Alles andere ist fighting against the architecture.
Die Kombination der beiden: struktureller Anker + native Primitives. Content-plus-Framing ist die Theorie, yieldMs-plus-notifyOnExit sind die konkreten Hebel. Zusammen ergibt das einen Kommunikations-Kanal zwischen CLI und Agent, der weder imperative noch fragil ist — er ist deklarativ und benutzt bereits existierende Infrastruktur.
Und das beste daran: beide Fixes erforderten null Änderungen in openclaw. Die gesamte Lösung lebt auf der CLI-Seite. Das ist das Adapter-statt-Replacement-Muster, das ich in meinem Hero-Launch-Post vor einer Woche zum ersten Mal formuliert habe, jetzt konkret angewendet: ich habe mich in openclaw's existierende Extension-Points (exit code als tool-result-status, yieldMs als background-yield-primitive, notifyOnExit als turn-re-trigger) eingeklinkt, statt openclaw selbst zu modifizieren.
Von 0.9.0 bis 0.10.1
Das Ganze passierte in einem einzigen Arbeits-Arc — 0.9.0 bis 0.10.1, mit mehreren Minor- und Patch-Versionen dazwischen. Jeder Release kam aus einer Live-Observation, nicht aus pre-planning. Ich habe etwas released, es gegen openclaw getestet, eine Divergenz zwischen Erwartung und Verhalten gefunden, den Fix eingebaut, den nächsten Release gemacht.
Zwei dieser Releases entstanden direkt aus derselben Frage an denselben Agent: "warum hast du nicht getan was du tun solltest?" Zwei Mal kam eine präzise, ehrliche Antwort — einmal über Aufmerksamkeit ("ich hab's schlicht ignoriert"), einmal über Architektur ("ich habe auf deine Nachricht reagiert"). Beide Antworten haben jeweils einen Release ausgelöst.
Das ist das wertvollste Rollen-Modell, das ich aus der Woche mitnehme. Nicht kürzere Release-Zyklen hinterherzujagen, sondern schneller in den Feedback-Loop zu kommen zwischen "ich glaube es funktioniert" und "hier zeigt mir die Realität, dass es nicht funktioniert." Und der schnellste Weg zu dieser Realität ist oft nicht das Logging, nicht das Tracing, nicht das Unit-Test-Schreiben — sondern einfach den Agent zu fragen, warum er das getan oder nicht getan hat was du erwartet hattest.
Das ist nicht bei jedem Problem möglich. Deterministische Systeme ignorieren solche Fragen. Aber LLM-Agents sind keine deterministischen Systeme. Sie haben eine Form von Selbstbeobachtung die sich auf Anfrage abrufen lässt. Nicht als Debugging-Ersatz, aber als schnelle erste Hypothese, bevor du in die tieferen Tools greifst. Zweimal heute hat mich die erste Hypothese direkt zur Lösung geführt.
Was als Nächstes
0.10.1 ist live auf npm. Die beiden Release-Loops der heutigen Session sind geschlossen. Was noch aussteht:
- Ein dediziertes Workflow-File, das der Agent per
apes workflow show async-grantabrufen kann, als protokoll-natives Gegenstück zur ad-hoc "For agents:"-Zeile. Die nächste Stufe jenseits "Content-plus-struktureller-Anker" Richtung "strukturiertes Agent-Protokoll mit eigenem Retrieval-Pfad". Noch nicht gebaut. - Ein Tripwire-Test, der einen echten Agent gegen den IdP durchlaufen lässt, um zu verifizieren, dass der async-grant-Flow korrekt durchgeht. Wäre die beste Regression-Guard, die ich haben könnte. Auch noch nicht gebaut.
Aber die Richtung ist klar. Und die Lektion, die mich wirklich beschäftigt, ist nicht die technische, sondern die methodische: wenn du an einem Tool arbeitest, das mit einem AI-Agent sprechen soll, frag den Agent direkt was er sieht und wie er es interpretiert. Nicht nur die Unit-Tests schreiben. Nicht nur die Specs dokumentieren. Den Agent fragen. Er ist oft überraschend ehrlich über seine eigenen Blindstellen — wenn du ihn nur fragst.
Was ist euer Muster dafür, wenn ein CLI-Tool einem AI-Agent etwas sagen soll dass er befolgen muss? Wenn ihr konkrete Beispiele habt: schickt sie mir gerne, ich sammle sie gerade.
@openape/apes@0.10.1 ist auf npm. Der Code liegt auf github.com/openape-ai/openape. Die vorigen Artikel dieser Serie erzählen wie OpenApe entstanden ist und wie der Weg hierher ging.